
Hello Haskellers!
Welcome to the third edition of the Parallel Haskell Digest, bringing you news, discussions and tasters of parallelism and concurrency in Haskell. The digest is made possible by the Parallel GHC project. More news about how we're doing below.
This digest is brought to you by Eric Kow and Nicolas Wu. Nick will be taking over as maintainer of the Parallel Digest for the next few months.
It's tutorial season in the Parallel Haskell world, with Simon Marlow's Parallel and Concurrent Programming in Haskell, and Don Stewart's Numeric Haskell: A Repa Tutorial. The former gives a broad tour of parallelism and concurrency techniques in Haskell and the latter focuses on the Repa parallel array library. Both are very concrete and focus on real working code. Give them a try!
News
Haskell in the Economist! The Economist article Parallel Bars discusses the rise of multicore computing, and the essential obstacle that programs have to be specially written with parallelism in mind. The article gives a tour of some problems (overhead and dependencies between subtasks, programmers being trained for sequential programming, debugging parallel programs) and possible solutions, among which is functional programming:
Meanwhile, a group of obscure programming languages used in academia seems to be making slow but steady progress, crunching large amounts of data in industrial applications and behind the scenes at large websites. Two examples are Erlang and Haskell, both of which are “functional programming” languages.
Are we doomed to succeed?
Word of the Month
The word of the month (well, phrase really!) for this digest is parallel arrays. Parallel array manipulation fits nicely into Haskell's arsenal of parallel processing techniques. In fact, you might have seen the Repa library, as mentioned above, in the news a while back. And now there's a new tutorial on the Haskell Wiki.
So what's all the fuss?
Parallel arrays manipulation is a particularly nice way of writing parallel programs: it's pure and it has the potential to scale very well to large numbers of CPUs. The main limitation is that not all programs can be written in this style. Parallel arrays are a way of doing data parallelism (as opposed to control parallelism).
Repa (REgular Parallel Arrays) is a Haskell library for high performance, regular, multi-dimensional parallel arrays. All numeric data is stored unboxed and functions written with the Repa combinators are automatically parallel. This means that you can write simple array code and get parallelism for free.
As an example, Repa has been used for real time edge detection using a Canny edge algorithm, which has resulted in performance comparable to the standard OpenCV library, an industry standard library of computer vision algorithms written in C and C++ (a single threaded Haskell implementation is about 4 times slower than the OpenCV implementation, but is on par when using 8 threads on large images).
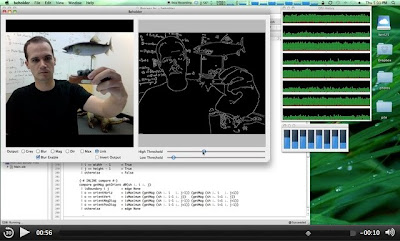
Repa performing Canny edge detection
While the Canny algorithm written with Repa doesn't quite match the speed of its procedural counterparts, it benefits from all of Haskell's built in support for purity and type safety, and painlessly scales to multiple cores. You can find more details on Ben Lippmeier's blog.
Parallel GHC project news
The Parallel GHC Project is an MSR-funded project to promote the real-world use of parallel Haskell. Part of this project involves effort by Well-Typed to provide tools for use by the general community.
Last week, Well-Typed were excited to announce that we have capacity to support another partner for the parallel project for at least another 12 months. So, if you have a project that involves scaling up to multiple cores, or that deals with some heavy duty concurrency, then we'd love to hear from you. In return for your time and commitment to the parallel project, we'll unleash our team of expert programmers to help build tools and provide support that will help you and the community towards making parallel Haskell even more accessible.
For more information on the Parallel GHC project, on the Parallel GHC Project wiki page
Blogs, papers and packages
Parallel and Concurrent Programming in Haskell (19 May)
Simon Marlow released version 1.1 of his tutorial introducing the main programming models available for concurrent and parallel programming in Haskell. "This tutorial takes a deliberately practical approach: most of the examples are real Haskell programs that you can compile, run, measure, modify and experiment with". The tutorial covers a lot of ground, including use of the new
Parmonad, so if you're still not sure where to start, this might be the place.Explicit speculative parallelism for Haskell's Par monad
Tomas Petricek builds off the Par monad to provide a way to write speculative computations in Haskell. If there are two different ways to compute something and each of the ways is faster for different kinds of input (but we don't know exactly which), one useful trick is to run both ways in parallel and return the result of the one that finishes first. Tomas' speculative
Parmonad lets you do just that, starting computations in parallel and cancelling unwanted ones. You can check his code out on GitHubEtage-Graph, data-flow based graph algorithms (3 Apr)
Mitar announced the Etage-Graph package, which implements graph algorithms on top of his data-flow framework. He invites us to have a look and see how one might implement known control-flow algorithms in a data-flow manner, which has the appeal of being easy to parallelise.
-
The stm-chans library offers a collection of channel types, similar to Control.Concurrent.STM.TChan but with additional features. It offers bounded, closable, and bounded closable FIFO channels, along with a partial TChan compatibility layer.
timeplot 0.3.0, Eugene Kirpichov (30 Apr)
Eugene Kirpichov announced the release of timeplot 0.3.0, a tool to help you visualize arbitrary time-dependent data, e.g. log files, into big picture visualisations. Eugene also linked to a presentation with plenty of graphical examples for the tool and its sister "splot", mostly on cluster computing use cases. The tools follow the basic philosophy of depending neither on the log format (the expected workflow is like
cat log | awk foo | plot), nor on the type of data (Eugene wants to visualise arbitrary signals).You can also find more information in Eugene's presentation.
Mailing list discussions
Weird multi-threading runtime behaviour of single-threaded program with GHC-7.0.3 (1 Apr) Herbert Valerio Riedel has a program which parses a roughly 8 MiB JSON file (with the aeson library) without any use of parallelism or concurrency constructs: just a straightforward, demanding, single-threaded computation. He compiled the program with
-threadedand ran with+RTS -N12on a 12 core machine. By rights, only one core should be doing work but when he looks at the output oftopit seems like all of them consume a substantial amount of CPU cycle. What's up with the remaining 11?A parallelization problem (25 Apr)
Wren Ng Thornton has some loopy code that he would like to parallelise. He was hoping to use pure parallelism (
parand friends) instead of explicit concurrency because he's concerned that "lightweight as Haskell's threads are [...] the overhead would swamp the benefits." Wren's code has an outer and inner loop fleshing out a map of maps. Wren wants to speed up his inner loop, which he thinks should be possible because the keys in the inner map are independent of each other.-
Yves Parès wants to build a simple game with multiple agents that communicate with each other. He asked if it was reasonable to launch one Haskell thread per agent and have them communicate over Chans (he will have something like 200 agents at a time). Felipe Lessa responded that hundreds of agents should be no problem but hundreds of thousands of agents might not work.
-
When experimenting with Repa and DPH, Wilfried Kirschenmann encountered strange compiler errors when parallelising his code; in particular, a strange pattern match failure in a do expression. Wilfried supplied a small demonstrator computing the norm of a vector. Ben Lippmeier responded with help and also a reminder that Repa and DPH are separate projects (the latter still being in the "research prototype" stage). Ben's version with more tweaks from Wilfried was 15x faster than his original (non-parallel?) version but still 15x slower than the C version. Parallelising the Repa sum and fold functions should help.
Service Component Architecture and Distributed Haskell (13 Apr)
James Keats noticed the recent talk about distributed Haskell and wished to see "interest from an experienced member of the Haskell community in implementing Haskell components with SCA/Tuscany", as this would help him to use Haskell in the same project with Java and Scala.
parallel-haskell mailing list (14 Apr)
Eric Kow announced the parallel-haskell mailing list and provided instructions for subscribing to the list. Whereas the Haskell Cafe list and Stack Overflow are the best places to ask your parallelism and concurrency questions, the parallel-haskell list is a great place to follow and discuss the research.
-
Among other questions about
seq, Andrew Coppin asked howpseqwas different from it. Austin Seipp responded that while pseq and seq are semantically equivalent, (A)pseqis only strict in its first argument whereasseqis strict in both and (B)pseqguarantees the order of evaluation so thatpseq a bmeansawill be strictly evaluated beforebwhereas for the purpose of potential optimisationsseqdoes not. Albert Y. C. Lai provided a short example showing that "there are non-unique evaluation orders to fulfill the mere strictness promise ofseq". select(2) or poll(2)-like function? (17 Apr)
Matthias Kilian wanted to know if the Haskell standard libraries had anything like a select or poll like function. Answering the immediate question, Don Stewart pointed to Control.Concurrent.threadWaitRead. Meanwhile, the thread opened into a long discussion on using high-level Haskell concurrency constructs vs. low-level polling.
For background,
select(along with variants like poll, epoll, kqueue, etc) is a system-call which is often used for asynchronous IO, concurrently doing some processing work while some IO operation is underway (Matthias' use case is "networking stuff listening on v4 and v6 sockets at the same time"). A typical way of using "select" or its cousins would be to implement an event-driven programming model with a "select loop": sleeping until some condition occurs on a file descriptor and, when woken, executing the appropriate bit of code depending on the file descriptor and the condition.Some programmers opt for this approach because they believe using processes and OS threads would be too inefficient. Ertugrul Soeylemez and others argue that this is unnecessary in Haskell because Haskell threads are so lightweight (epoll under the hood); we can just stick with high-level concurrency constructs and trust the compiler and RTS to be smarter than us.
On the other hand, Mike Meyer is sceptical about the scalability and robustness of this solution. The sort of code Mike wants to write is for systems "that run 7x24 for weeks or even months on end [where] [h]ardware hiccups, network failures, bogus input, hung clients, etc. are all just facts of life." Using
selectloops in his experience is not about efficiency, but avoiding the problems that arise from using high-level concurrency constructs in other languages. He favours to achieve concurrency with a "more robust and understandable" approach using separate Unix processes and an event-driven programming model. So far the only high-level approach Mike has found that provides for the sort of scalability is Eiffel's SCOOPHow does Haskell stack up? And what about Haskell for the Cloud?
Killing threads in foreign calls. (17 Apr)
Jason Dusek is building an application using Postgres for storage (with the help of the libpq binding on Hackage). He would like to kill off threads for queries that take too long to run, but trying Control.Concurrent.killThread seems not to work. This turns out to be a fairly non-trivial problem: most C code is not written to gracefully handle things like its underlying OS thread being killed off. The solution is to use whatever graceful cancellation mechanism is supplied by the foreign library; the PGCancel procedure in Jason's case.
Painless parallelization. (19 Apr)
Grigory Sarnitskiy believes that parallel programming is actually easier than sequential programming because it allows one "to avoid sophisticated algorithms that were developed to gain performance on sequential architecture". So what are his options (preferably "release state" for writing pure functional parallel code with a Haskellish level of abstraction? Mats Rauhala pointed Grigory to the use of
parandpseq, and the RWH chapter on parallelism and concurrency. Don Stewart followed up with a list of options:- the "parallel" package Repa (parallel arrays)
- DPH (experimental)
- using concurrency
Grigory's question also prompted Eric Kow to prioritise the Parallel Haskell portal. Hopefully it will give us a standard resource to point new parallel Haskellers like Grigory to.
Stack Overflow
- Howto kill a thread in Haskell
- Comparing Haskell threads to kernel threads - is my benchmark viable?
- Fair concurrent
mapfunction in haskell? - Program crashing when trying to create multiple threads
- A way to form a 'select' on MVars without polling.
- Haskell lightweight threads overhead and use on multicores
- Haskell repa - mapping with indices
- Do Accelerate and Repa have different use cases?
Help and feedback
Got something for the digest? Send us an email at . We're particularly interested in short parallelism/concurrency puzzles, and cool projects for featured code. Other comments and feedback (criticism and corrections especially!) would be welcome too.