
In part 1 we looked at an overview of all the various problems that make up “Cabal hell”. We also looked at an overview of a few solutions and how they overlap.
In part 2 and part 3 we’ll look in more detail at the two major solutions to Cabal hell. In this post we’ll look at Nix-style package management, and in the next post we’ll look at curated package collections.
A reminder about what the problems are
You might recall from part 1 this slightly weird diagram of the symptoms of Cabal Hell:
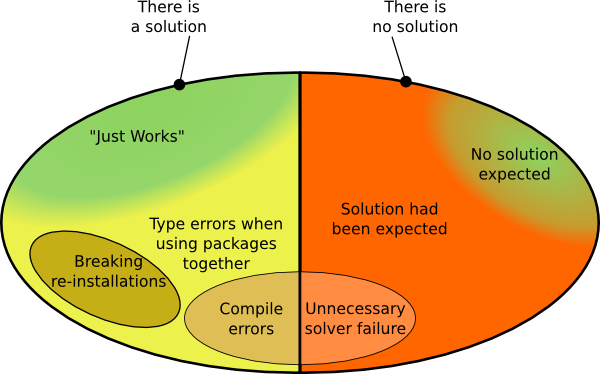
In this part we’re going to pick out a couple of the problems and look them in a bit more detail:
- Breaking re-installations
- Type errors when using packages together
Breaking re-installations
There are situations where Cabal’s chosen solution would involve reinstalling an existing version of a package but built with different dependencies.
For example, suppose I have an application app and it depends on zlib and
bytestring. The zlib package also depends on bytestring. Initially the
versions I am using for my app-1.0 are zlib-0.5 and bytestring-0.9
(Versions simplified for presentation.) Now I decide in the next version of my
app, app-1.1, that I want to use a nice
new feature in bytestring version 0.10. So I ask cabal to build my
application using a more recent bytestring. The cabal tool will come up
with a solution using the new bytestring-0.10 and the same old version of
zlib-0.5. Building this solution will involve
installing bytestring-0.10 and rebuilding zlib-0.5 against it.
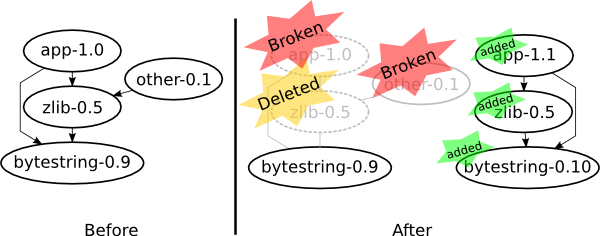
- What is the problem here?
-
The problem is the rebuilding of
zlib-0.5. - Why is this a problem?
-
It is a problem because when we install the instance “
zlib-0.5built againstbytestring-0.10” we have to delete the pre-existing instance “zlib-0.5built againstbytestring-0.9”. Anything that depended on that previous instance now has a dangling reference and so is effectively broken. - Why do we have to delete the previous instance?
-
The way installed packages are managed is such that each GHC package database can only have one instance of each package version. Note that having two different versions would be allowed, e.g.
zlib-0.4andzlib-0.5, but having two instances ofzlib-0.5is not allowed. Not deleting the previous instance would involve having two instances ofzlib-0.5(each instance built against different versions ofbytestring).
So the root of the problem is having to delete – or if you like, mutate – package instances when installing new packages. Mutable state strikes again! And this is due to the limitation of only being able to have one instance of a package version installed at once.
Type errors when using packages together
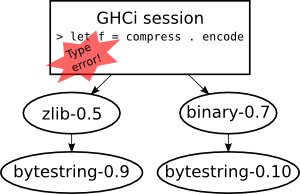
The second, orthogonal, problem is that it is possible to install two packages and then load them both in GHCi and find that you get type errors when composing things defined in the two different packages. Effectively you cannot use these two particular installed packages together.
The reason is that the two packages have been built using different versions of
some common dependency. For example, I might have zlib built against
bytestring-0.9 and binary built against bytestring-0.10.
Now if I try to use them together in GHCi (e.g. compressing the result of
binary serialisation) then I will get a type error from GHC saying that
bytestring-0.9:Data.ByteString.ByteString is not the same type as
bytestring-0.10:Data.ByteString.ByteString. And GHC is not wrong here, we
really cannot pretend that these are the same types (at least not in general).
This is a variant on the classic “diamond dependency problem” that
cabal solved years ago. So why do we still get it? In fact we never hit
this problem when building a package with cabal, because
cabal’s solver looks for “consistent” solutions. (Recall from part 1,
that when we say a “consistent” solution we mean one that uses only one version
of any package.)
We can still hit this problem when we install things separately and then use
the packages directly with ghc or ghci. This is because cabal does
not enforce consistency in the developer’s environment. It only enforces
consistency within any set of packages it installs simultaneously.
The fundamental problem is that developers expect to be able to use combinations of their installed packages together, but the package tools do not enforce consistency of the developer’s environment.
In practice this class of problem is currently relatively rare. In part that is because one would often hit the problem above involving re-installing and breaking packages. If however we lifted the limitation on installing multiple instances of the same version of a package, then we would always be able to install new versions and we would instead hit this problem much more frequently.
Nix-style package management
The ideas behind Nix are now over 10 years old. When first reading the published papers on Nix some years ago I was struck by how simple and elegant they are. They also appear to work well in practice, with a full Linux distribution based on them, plus a number of other well-regarded tools.
The key ideas are:
A persistent package store. That is, persistent in the sense of an immutable functional data type. Packages are added but never mutated. Old packages can be garbage collected. Just like immutable data structures in Haskell, immutable package stores have several advantages.
Working environment(s) that are “views” into the package store. A working environment has a number of packages available, and this is just a subset of all the packages that are installed in the package store. There can be many of these that co-exist and switching the view is simple and cheap.
Contrast this to a traditional approach, e.g. what we have now with Cabal, or
Linux distros based on .rpm or .deb. In the traditional approach there is
a single environment which is exactly the same as the full set of installed
packages. So compared to a traditional approach, we have an extra level of
indirection. Having views lets us have a much larger collection of packages
installed than we have available in the working environment, and allows
multiple environments.
A good illustration of what these ideas give us is to see what happens when we want to add a new package:
We start with our initial environment which points to a bunch of packages from the store.
We compile and install a new package into the store. So far this changes very little, which is a big feature! In particular it cannot break anything. The new installed package can co-exist with all the existing ones. There can be no conflicts (the install paths are arranged to guarantee this). No existing packages have been modified or broken. No environments have yet been changed.
Now we have choices about what to do with environments. Our existing environment is unchanged and does not contain the new package. We can create a new environment that consists of the old environment with the extra package added. In principle both the old and the new environments exist. This is very much like a persistent functional data structure:
let env' = Map.insert pkgname pkg envBoth exist, the old one is not changed, and we can decide if we are only interested in the new one or if we want to keep both.
Finally we can, if we want, switch our “current” environment to be the new environment with the new package. So while multiple environments can exist, only one of them is active in our current shell session.
So what have we gained from the added indirection of a persistent store + views?
We can install new things without breaking anything, guaranteed.
We get atomic rollback if we don’t like the changes we made.
Multiple independent environments.
Environments that are very cheap to create.
The multiple environments effectively gives us sandboxes for free. In fact it’s better because we can easily share artefacts between sandboxes when we want to. That means far fewer rebuilds, and easy global installation of things built in an isolated environment.
Nix has a few other good ideas, like its functional package description language and some clever tricks for dealing with the messy details of system packages. The key ideas however are the ones I’ve just outlined, and they are the ones that we should steal for GHC/Cabal.
Mechanisms, policies and workflows
The package store and the multiple environments are just a mechanism, not a user interface. The mechanisms are also mostly policy free.
Generally we should start from user requirements, use cases, workflows and the like, and work out a user interface and then decide on mechanisms that will support that user interface. That said, I think it is clear that the Nix mechanisms are sound and sufficiently general and flexible that they will cover pretty much any user interface we decide we want.
So I think our design process should be:
Look at the packaging tool requirements, use cases, workflows etc, and work out a user interface design.
Then figure out how the actions in that user interface translate into operations on the Nix package store and environments.
Addressing the Cabal Hell problems
The Nix approach deals nicely with the problem of breaking re-installations. The Nix mechanisms guarantee that installed packages are never mutated, so no existing installed packages ever break.
The Nix mechanisms do not deal directly with the issue of type errors when using packages together. As we noted before, that requires enforcing the consistency of the developer’s environment. In Nix terms this is a policy about how we manage the Nix environment(s). The policy would be that each environment contains only one version of each package and it would guarantee that all packages in an environment can be used together.
Without wishing to prejudge the future user interface for cabal, I think this
is a policy that we should adopt.
Enforcing consistency does have implications for the user interface. There will be situations where one wants to install a new package, but it is impossible to add it to the current environment while keeping all of the existing packages. For example, suppose we have two different web stacks that have many packages in common but that require different versions of some common package. In that case we could not have a consistent environment that contains both. Thus the user interface will have to do something when the user asks to add the second web stack to an environment that already contains the first. The user interface could minimise the problem by encouraging a style of use where most environments are quite small, but it cannot be avoided in general.
While what I am suggesting for consistency is relatively strong, we cannot get away without enforcing some restrictions on the environment. For example if our environment did contain two instances of the same version of a package then which one would we get when we launch GHCi? So my view is that given that we cannot avoid the user interface issues with environment consistency, it is better to go for the stronger and more useful form.
In fact we’ve already been experimenting in this direction. The current cabal
sandbox feature does enforce consistency within each sandbox. This seems to
work ok in practice because each sandbox environment is relatively small and
focused on one project. Interestingly we have had some pressure to relax this
constraint due to the cost of creating new sandboxes in terms of compiling.
(Allowing some inconsistencies in the environment allows the common packages to
be shared and thus only compiled once.) Fortunately this issue is one that is
nicely solved by Nix environments which are extremely cheap to create because
they allow sharing of installed packages.
Implementation progress
We’ve been making small steps towards the Nix design for many years now. Several years ago we changed GHC’s package database to use the long opaque package identifiers that are necessary to distinguish package instances.
More recently Philipp Schuster did a GSoC project looking into the details of what we need to do to incorporate the Nix ideas within GHC and Cabal. You can see the slides and video of his HiW presentation. We learned a lot, including that there’s quite a lot of work left to do.
Last year Edward Yang and Simon PJ (with advice from Simon Marlow and myself) started working on implementing the “Backpack” package system idea within GHC and Cabal. Backpack also needs to be able to manage multiple instances of packages with the same version (but different deps) and so it overlaps quite a lot with what we need for Nix-style package management in GHC. So Edward’s work has dealt with many of the issues in GHC that will be needed for Nix-style package management.
Another small step is that in GHC 7.10 we finally have the ability to register multiple instances of the same version of a package, and we have the basic mechanism in GHC to support multiple cheap environments (using environment files). Both of these new GHC features are opt-in so that they do not break existing tools.
The remaining work is primarily in the cabal tool. In particular we have to
think carefully about the new user interface and how it maps into the Nix
mechanisms.
So there has been a lot of progress and if we can keep making small useful steps then I think we can get there. Of course it would help to focus development efforts on it, perhaps with a hackathon or two.
Conclusion
Implementing the Nix approach in GHC/Cabal would cover a major part of the Cabal Hell problems.
In the next post we’ll look at curated package collections, which solves a different (but slightly overlapping) set of Cabal Hell problems. Nix-style package management and curated package collections are mostly complementary and we want both.